面试中可能会遇到这样的问题:接口可以实现接口吗?ans:不可以实现,但是可以继承一个或多个接口.抽象类可以实现接口吗?ans:可以接口默认的修饰符所有的接口的成员变量默认都是:puiblicstaticfinal的所有接口的方法默认都是:publicabstract如果你只想用A接口中的某一个方法,可以写一个抽象类实现A接口,然后实现你想用的那个方法,方法体可以为空,在具体的实现类里面继承抽象类,然后实现抽象类中的方法即可接口和抽象类的区别:抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。抽象类要被子类继承,接口要被类实现。接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
public interface IEat extends IEat2,IEat3{
public default int haveBreakFast(){
return 0;
}
public abstract int haveBreakFast2();
}接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
抽象方法只能申明,不能实现,接口是设计的结果,抽象类是重构的结果
抽象类里可以没有抽象方法
抽象方法要被实现,所以不能是静态的,也不能是私有的。
接口可继承接口,并可多继承接口,但类只能单继承。
事务的4种隔离级别
.未提交读(readuncommitte:会出现脏读、不可重复读和幻读。脏读的设计只是为了提供非阻塞读,但是对于oracle来说,默认就提供非阻塞读,
即查询不会受到任何增删改操作的影像,因为oracle提供了undo来存放更新前的数据。
.提交读(readcommitte:会出现不可重复读和幻读。oracle的默认事务隔离级别。
.重复读(repeatablerea:会出现幻读。
.串行化(serializabl:隔离级别最高,不允许出现脏读、不可重复读和幻读。即一个事务执行结束了另一个事务才能执行。当然并发性也就最差。
除了这四种,oracle还提供readonly隔离级别,即只支持读,在该级别中,该事务只能看到事务开始那一刻提交的修改。
脏读:一个事务可以读物另一个事务未提交的数据。
不可重复读:在一个事务中不同时间段查询出现不同的结果,可能被更新可能被删除。
幻读:在一个事务中不同时间段查询,记录数不同。与不可重复读的区别是:在幻读中,已经读取的数据不会改变,只是与以前相比,会有更多的数据满足查询条件。
Cloneable接口是一个空接口,仅用于标记对象,Cloneable接口里面是没有clone()方法,里面的的clone()方法是Object类里面的方法!默认实现是一个Native方法。
所有的类默认继承Object类
浅拷贝是指拷贝对象时仅仅拷贝对象本身,而不拷贝对象包含的引用指向的对象。深拷贝不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象。举例来说更加清楚:对象A1中包含对B1的引用,B1中包含对C1的引用。浅拷贝A1得到AA2中依然包含对B1的引用,B1中依然包含对C1的引用。深拷贝则是对浅拷贝的递归,深拷贝A1得到AA2中包含对B2的引用,B2中包含对C2的引用。
若不对clone()方法进行改写,则调用此方法得到的对象即为浅拷贝
equals方法在object中依然是==来比较的,也就是比较的是两个对象的引用地址。而String方法中重写了equals方法一下是Object和String中的源码:
//Object中的equals方法
public boolean equals(Object obj) {
return (this == obj);
}
//String中的equals方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}java异常结构
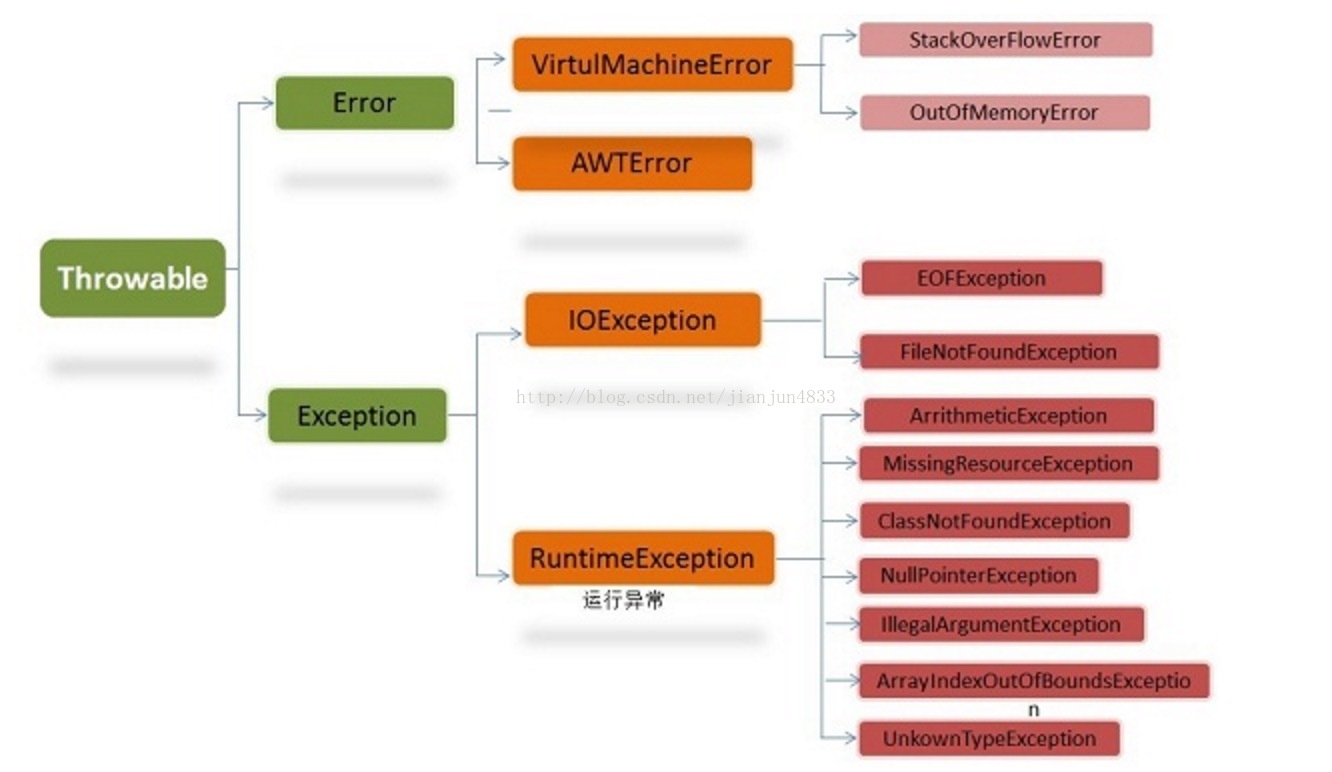
补充:trycatchfinally
try中的return语句调用的函数先于finally中调用的函数执行,也就是说return语句先执行,finally语句后执行,返回的结果是return并不是让函数马上返回,而是return语句执行后,将把返回结果放置进函数栈中,此时函数并不是马上返回,它要执行finally语句后才真正开始返回。
索引的优化问题
where,having,orderby,groupby等会使用到索引
索引失效的情况:
如果使用like则只有xx%这种形式才会使用索引;
如果where中是or的关系,或NOTIN或<>,则索引无效
复合索引:
如果是联合索引ab字段则a,ab,会使用索引b不会使用索引需要单独建立符合最左原则
mysql的存储引擎:
MyISAM不支持事务,用于只读程序提高性能。数据文件(.MY,索引文件(.MY和结构文件(.fr
InnoDB支持acid事务,行几锁,并发
BerkeleyDB支持事务
union和unionall的区别
UNION操作符用于合并两个或多个SELECT语句的结果集。
请注意,UNION内部的SELECT语句必须拥有相同数量的列。列也必须拥有相似的数据类型。每条SELECT语句中的列的顺序必须相同。
union和unionall的区别是,union会自动过滤多个结果集合中的重复结果,而unionall则将所有的结果全部显示出来,不管是不是重复。所以unionall的效率会高很多Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;UnionAll:对两个结果集进行并集操作,包括重复行,不进行排序;Intersect:对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;Minus:对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。可以在最后一个结果集中指定Orderby子句改变排序方式。
leftjoin(左联接)返回包括左表中的所有记录和右表中联结字段相等的记录rightjoin(右联接)返回包括右表中的所有记录和左表中联结字段相等的记录innerjoin(等值连接)只返回两个表中联结字段相等的行
0.将字符串中的第一个,号替换成-,第二个替换成;
Strings='1989,0,25';s=s.replaceFirst(',','-').replaceFirst(',',':');
看下一下代码能否实现0依次减去0.0.0......直至减到0;
Double num = 1.0;
for (Double i = 0.1d; i <= num; i += 0.1) {
System.out.println('i' + i);
num -= i;
System.out.println(num);
}ans:不能,这里主要考察double精度的问题。
总结:
Java中的简单浮点数类型float和double不能够进行运算,因为大多数情况下是正常的,但是偶尔会出现如上所示的问题。这个问题其实不是JAVA的bug,因为计算机本身是二进制的,而浮点数实际上只是个近似值,所以从二进制转化为十进制浮点数时,精度容易丢失,导致精度下降。
要保证精度就要使用BigDecimal类,而且不能直接从double直接转BigDecimal,要将double转string再转BigDecimal。也就是不能使用BigDecimal(doubleva方法,你会发现没有效果。要使用BigDecimal(Stringva方法。
string字符串有没有长度限制
抄一下:
我们可以使用串接操作符得到一个长度更长的字符串,那么,String对象最多能容纳多少字符呢?查看String的源代码我们可以得知类String中
是使用域 count 来记录对象字符的数量,而count 的类型为 int,因此,我们可以推测最长的长度为 2^32,也就是4G。
不过,我们在编写源代码的时候,如果使用 Sting str = 'aaaa';的形式定义一个字符串,那么双引号里面的ASCII字符最多只能
有 65534 个。为什么呢?因为在class文件的规范中, CONSTANT_Utf8_info表中使用一个16位的无符号整数来记录字符串的长
度的,最多能表示 65536个字节,而java class 文件是使用一种变体UTF-8格式来存放字符的,null值使用两个字节来表示,因此只
下 65536- 2 = 65534个字节。也正是变体UTF-8的原因,如果字符串中含有中文等非ASCII字符,那么双引号中字符的数量会更(一个中文字符占用三个字节)。如果超出这个数量,在编译的时候编译器会报错.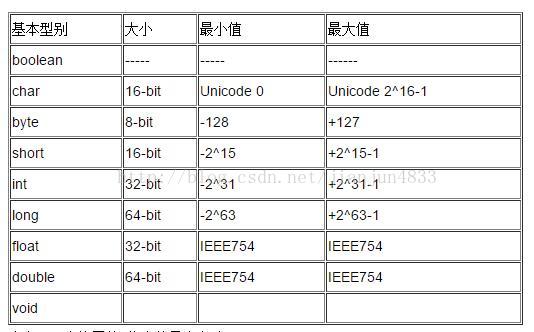
info可以看到所有库的key数量
dbsize则是当前库key的数量
keys*这种数据量小还可以,大的时候可以直接搞死生产环境。
dbsize和keys*统计的key数可能是不一样的,如果没记错的话,keys*统计的是当前db有效的key,而dbsize统计的是所有未被销毁的key
初始化顺序
没有子类:静态块/静态变量(谁在前先执行谁)->构造块/构造方法(先构造块)
有子类:父类静态块/父类静态变量(谁在前先执行谁)->子类父类静态块/父类静态变量(谁在前先执行谁)->父类构造块/构造方法(先构造块)->子类构造块/构造方法(先构造块)
静态块只执行一次,构造块/构造方法每new一次类就会执行一次
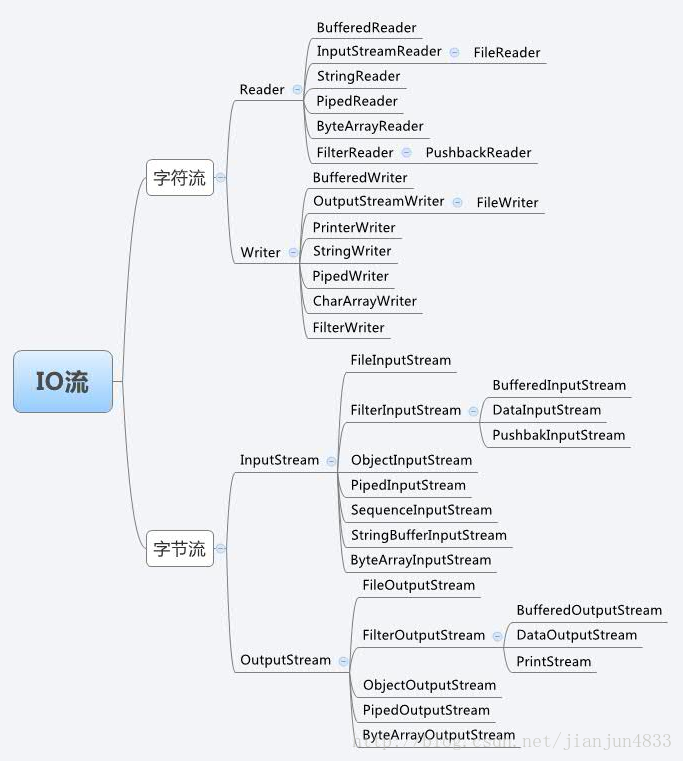
下面哪个流类属于面向字符的输入流()
答案:D解析:Java的IO操作中有面向字节(Byt和面向字符(Character)两种方式。面向字节的操作为以8位为单位对二进制的数据进行操作,对数据不进行转换,这些类都是InputStream和OutputStream的子类。面向字符的操作为以字符为单位对数据进行操作,在读的时候将二进制数据转为字符,在写的时候将字符转为二进制数据,这些类都是Reader和Writer的子类。总结:以InputStream/OutputStream为后缀的是字节流;以Reader/Writer为后缀的是字符流。扩展:Java流类结构,一目了然,解决大部分选择题:
springioc注入方式有说3种的
a、接口注入;b、setter方法注入;c、构造方法注入;
有说四种的:
Set注入构造器注入静态工厂的方法注入实例工厂的方法注入
创建线程的两种方式:
继承Thread类,并重写run();
实现runnable接口,并实现run();

待补充:

子父类中如果方法被重写new谁就调谁的方法,如果是静态的话则前面的类型是谁则就调用谁的方法,静态方法不能被重写1hashMap的实现原理
hashMap是基于数组➕链表的数据结构存储,初始化长度为16,put方法时,先判断key是否为空,为空的话直接放在位置0,否则,计算key的hash值,然后根据hash值计算下标,根据下标取出entry链表,for循环,如果key的值已经存在,则替换旧的value,并返回oldvalue;,否则的话就调用addEntry方法,添加新的.get(key)的时候,则首先判断key是否为空,为空则获取key为null的value并返回.否则计算key的hash值,然后根据hash值,获取索引位置,根据索引获取Entry链表,for循环如果hash值相等,并且key==key获取key.equals(key)则返回value;hashmap和hashtable区别:线程是否安全,hashtable是线程安全的方法由synchronized修饰2是否允许null键值对,hahsMap允许,另一个会抛出null指针异常.
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} final Entry getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
文章为作者独立观点,不代表 股票程序化软件自动交易接口观点



股民评论