
机器学习作为一种人工智能领域的技术,应用越来越广泛。可以帮助我们解决分类、回归、聚类等许多问题,更好的效果经常需要模型具有较大的容量来提升模型的精度和泛化能力。过度增加模型的容量也容易导致过度拟合现象,即模型在训练集上表现很好,但在新数据上的性能较差。正则化技术的引入非常重要。
正则化技术是一种常见的方法,用于减少机器学习模型的复杂程度并提高其泛化能力。正则化技术通常基于在模型设定的损失函数中加入一个额外的约束条件。这个约束条件可以限制模型参数的值的范围。与其他机器学习技术结合使用,如线性回归和逻辑回归,正则化技术可以有效地减少过拟合问题,并增加模型的普适性和稳健性。
其中,L1正则化和L2正则化是两种常见形式的正则化技术。L1正则化以参数权重绝对值之和作为惩罚项,可以导致大量的参数权重为零,从而实现特征选择。L2正则化是以参数权重二次方之和作为惩罚项,可以使得参数权重变得更加平滑,从而缓解过度拟合的问题。正则化技术在机器学习和深度学习领域都非常普遍,并且一些研究取得了重要进展。在实际应用中,引入正则化技术是很有必要的,以避免算法失败的场景并提高算法的准确性和性能。
提示:以下是本篇文章正文内容。
L2正则化的原理
L2正则化又称为权重衰减,是一种用于减少模型泛化误差的常用技巧。它通过向模型的损失函数添加一个惩罚项,来防止模型过度拟合训练数据,从而提高了模型的泛化能力。
在L2正则化中,我们在损失函数中添加一个L2范数惩罚项,它是所有参数的平方和的平方根,这样就会在参数向量中大幅减少每个元素的值,降低模型复杂度。
具体来说,给定一个参数向量,L2正则化通常是将损失函数改写为:



其中,是模型的平均损失,是参数向量的L2范数,是超参数,用于控制L2正则化的力度。



当越大时,正则化惩罚项就越大,模型在学习过程中会更加倾向于选择较小的参数向量,这样训练出的模型参数更加接近零,容易实现功能相当的屏蔽或选择。而当趋近于0时,L2正则化的惩罚几乎不起作用,模型就会比较容易过拟合训练数据。
总体来说,L2正则化可以有效的使决策边界更平滑且量级较小,同时也降低了特征之间的依赖度,避免出现过拟合现象,提高了模型的稳定性和泛化能力。L2正则化是一种非常优秀的解决方案,应用广泛,在应用深度学习的交叉学科中被广泛讨论。
为什么L2正则化可以防止过拟合?
原因解释
通过引入正则化项,L2正则化可以有效控制模型过于复杂,过拟合的情况。L2正则化还可以使模型具有更好的泛化能力,从而适用于更多的数据集。总之,L2正则化通过对权重进行约束,降低模型复杂度,减少过拟合的风险,提高模型的泛化能力。
为什么权重大就更可能导致过拟合?
权重大了可能会导致过拟合的原因有几个方面:
过大的权重会导致模型对于训练数据的细节特征过度拟合,而无法泛化到新的数据上,导致过拟合。过大的权重也会导致模型的复杂度增加,这会增加模型对于数据的拟合能力,但同时也会降低模型的泛化能力,因为模型可能会学习到训练数据的噪声和不必要的特征。过大的权重也会导致模型的优化难度加大,因为梯度下降等优化算法可能会因为权重过大而无法收敛。
举例说明
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
# 生成数据
np.random.seed(10)
X = np.linspace(0, 1, 10)
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.2, len(X))
X_test = np.linspace(0, 1, 100)
y_test = np.sin(2 * np.pi * X_test) + np.random.normal(0, 0.2, len(X_test))
# 不同的模型复杂度
degrees = [1, 3, 10]
X = X[:, np.newaxis]
X_test = X_test[:, np.newaxis]
# 绘制结果
plt.figure(figsize=(18, 6))
for i in range(len(degrees)):
plt.subplot(1, len(degrees), i+1)
degree = degrees[i]
# 标准多项式拟合
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=0))
model.fit(X, y)
y_poly_pred = model.predict(X_test)
plt.plot(X_test,y_test, color="red", label="True function")
plt.plot(X_test, y_poly_pred, color="blue", label="Polynomial fit (no L2)")
plt.scatter(X, y, color="navy", s=40, marker="o", label="training points")
# 将多项式拟合添加L2正则化
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=0.1))
model.fit(X, y)
y_poly_pred = model.predict(X_test)
plt.plot(X_test, y_poly_pred, color="orange", label="Polynomial fit (with L2)")
plt.ylim(-2, 2)
plt.legend(loc="best")
plt.title("Degree {}
Train Score: {:.3f}, Test Score: {:.3f}".format(
degree, model.score(X, y), model.score(X_test, y_test)))
plt.show()运行结果如下:
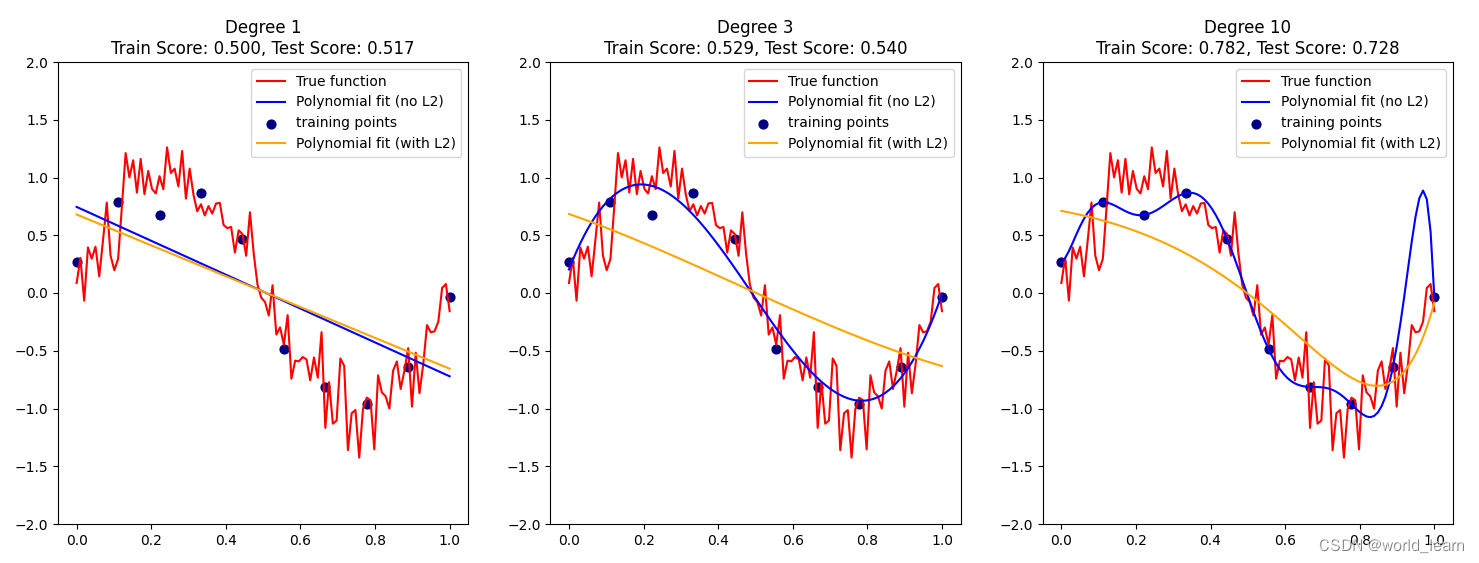
上述代码绘制了三个不同多项式阶数的拟合结果,其中红色线表示原始函数,蓝色线和橙色线分别为拟合结果无L2正则化和使用L2正则化的模型拟合得到的函数。
从中我们可以看出,在没有使用L2正则化的情况下,多项式模型很容易在训练集上拟合数据,但泛化能力差,即测试集上表现不佳。但是当引入了L2正则化之后,模型泛化能力得到提升,即使多项式项较多时(degree=,使用L2正则化也避免了过拟合,并提高了模型性能和稳定性。这就是L2正则化的实际效果。
为了避免权重过大导致的过拟合问题,通常会使用正则化技术,如L2正则化,通过对权重进行限制,使其不会过大,从而减少过拟合的风险。正则化也可以在训练过程中平衡拟合性和泛化性,提高模型的性能和可靠性。
在L2正则化中,参数向量中的每个元素都会受到惩罚,这就鼓励模型使用尽量少但足够表示模型的参数来解决问题。应用正确的正则化可以大大提高模型的泛化能力,并防止模型在训练集上出现过度拟合现象。
补充:其他正则化技术
正则化技术是用于减少模型过度拟合风险的一组技术。它们通常基于损失函数添加额外的惩罚项,以减少模型中一些不必要的参数或特征,并提高模型泛化能力。常用的正则化技术主要有以下几种:
L1正则化:对模型的权重绝对值之和0加权,通过使绝大多数参数变为0从而达到特征选择的目的。L2正则化:对模型的平方和加权,使模型参数更加平滑和稳定,降低过拟合风险。Dropout正则化:随机地让一些神经元失活,避免特定的神经元对特征的过度依赖,从而增强模型健壮性。Earlystopping:在训练期间监控模型的验证误差,当验证误差开始增加时停止训练。Max-Norm正则化:限制每个神经元的权重的范数,避免过度依赖一个很小的数量的特征,增加模型泛化性能。ElasticNet正则化:综合使用L1和L2正则化的方法,融合特征选择和模型稳定性。
除了上述方法,还有其他的正则化技术可以使用,如BatchNormalization、DropConnect等。正则化技术的使用可以提高模型泛化能力,避免过度拟合,并提高模型的准确性和稳健性。
文章为作者独立观点,不代表 股票程序化软件自动交易接口观点




股民评论