根据一个longurl生成一个shorturl。
根据shorturl还原longurl,并跳转:
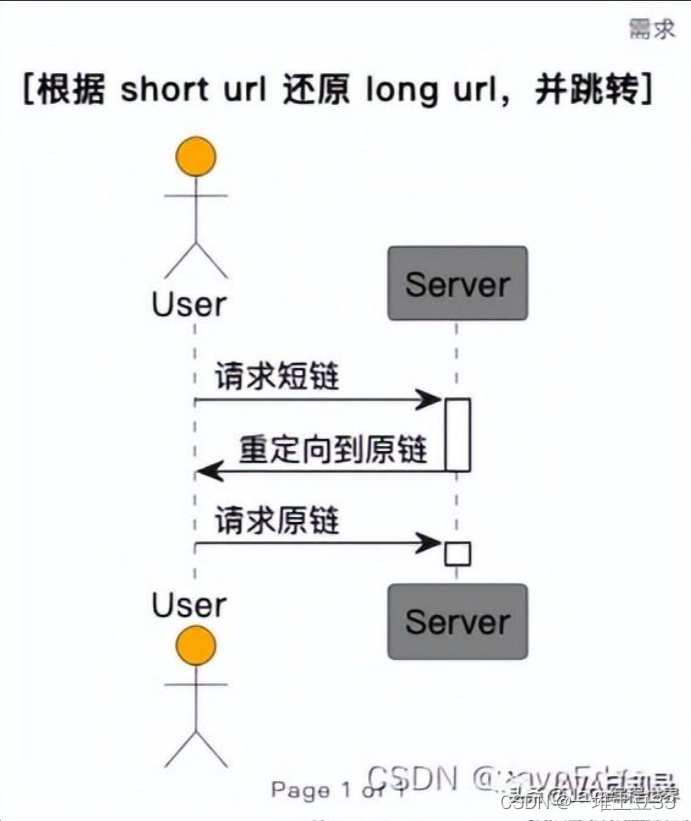
需和面试官确认的问题:
longurl和shorturl必须一一对应吗?
Shorturl长时间没人用,需要释放吗?
1QPS分析
问日活,如微博100M推算产生一条tinyurl的qps假设每个用户平均每天0.1条带URL的微博平均写QPS=100M*0.1/86400=100峰值写qps=100*2=200推算点击一条tinyurl的qps假设每个用户平均点1个tinyurl平均写QPS=100M*1/86400=1k峰值读qps=1k*2=2kdeduce每天产生的新URL所占存储100M*0.1=10M条每条URL长度平均按100算,共1G1T硬盘能用3年
由3分析可知,并不需要分布式或者sharding,支持2kQPS,一台SSDMySQL即可。
2Service服务-逻辑块聚类与接口设计
该系统其实很简单,只需要有一个service即可:URLService。由于tinyurl只有一个UrlService:
本身其实就是个小的独立应用也无需关心其他任何业务功能
方法设计:
UrlService.encode:编码方法
UrlService.decode:解码方法
访问端口设计,当前有如下两种常用主流风格:
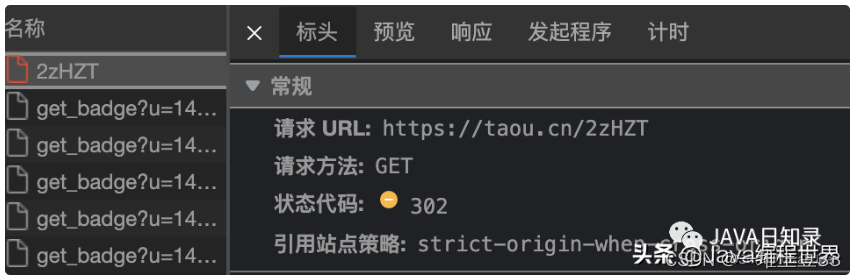
POST/data/shorten
你们公司的短链系统是选择哪种服务设计呢?
3Storage数据存取
select选存储结构scheme细化数据表
需要事务吗?No,nosql+1
需要丰富的sqlquery吗?no,nosql+1
想偷懒吗?tinyurl需要写的代码不复杂,nosql+1
qps高吗?2k,不高。sql+1
scalability要求多高?存储和qps都不高,单机都能搞定。sql+1
- sql 需要自己写代码来 scale
- nosql,这些都帮你做了
是否需要sequentialID?取决于你的算法
2算法
longur转成一个6位的shorturl。给出一个长网址,返回一个短网址。
实现两个方法:
标准:
短网址的key的长度应为可用字符只有[a-zA-Z0-9].比如:abcD9E任意两个长的url不会对应成同一个短url,反之亦然。
用两个哈希表:
一个是短网址映射到长网址一个是长网址映射到短网址
为避免重复,我们可以按照字典序依次使用,或者在随机生成的基础上用一个集合来记录是否使用过。
使用哈希函数
如取longurl的MD5的最后6位:
快难以设计一个无哈希冲突的哈希算法
随机生成shortURL+DB去重
随机取一个6位的shortURL,若没使用过,就绑定到改longurl。
优点:实现简单
缺点:生成短链接的速度,随着短链接越多而越慢
关系型数据库表:只需Shortkey和longurl两列,并分别建立索引
也可使用nosql,但需要建立两张表:

根据long查询shortkey=longurl列=shorturlvalue=nullortimestamp根据short查询longkey=shorturl列=longurlvalue=nullortimestamp
进制转换Base32
将6位shorturl看做一个62进制数每个shorturl对应到一个整数该整数对应DB表的主键
6位可表示的不同URL:
5位=62^5=0.9B=9亿6位=62^6=57B=570亿7位=62^7=5T=35000亿
优点:效率高
缺点:强依赖于全局的自增id
因为要用到自增id,所以只能用关系型DB表:
id主键、longurl
如何提高响应速度,和直接打开原链接一样的效率。
明确,这是个读多写少业务。
1缓存提速
缓存需存储两类数据:
long2shortshort2long
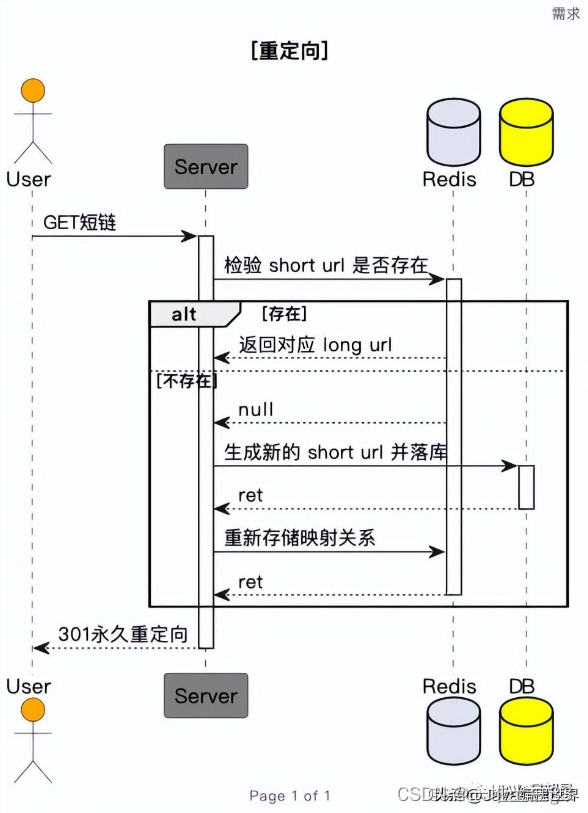
利用地理位置信息提速。
优化服务器访问速度:
不同地区,使用通不同web服务器通过dns解析不同地区用户到不同服务器
优化数据访问速度
使用中心化的MySQL+分布式的Redis一个MySQL配多个Redis,Redis跨地区分布
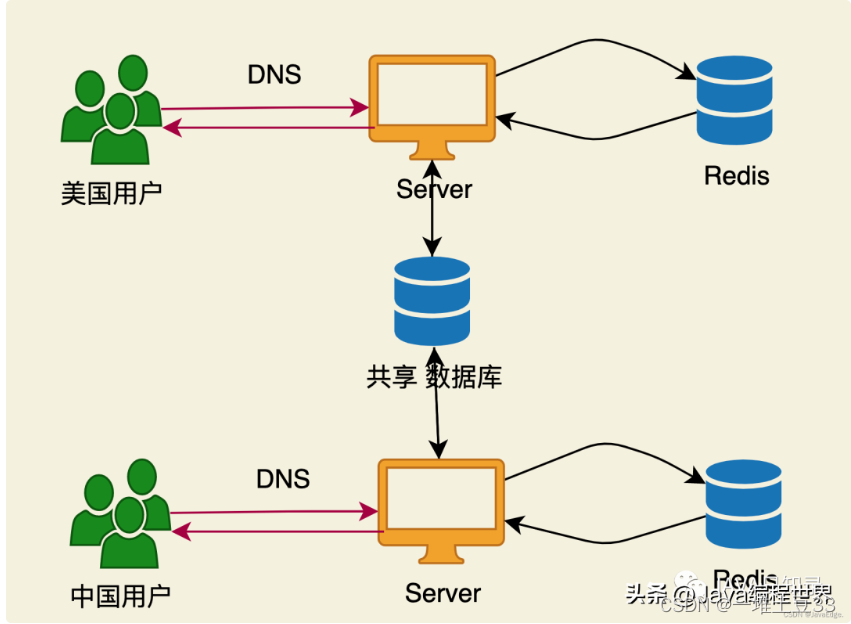
3何时需要多台DB服务器
cache资源不够或命中率低
写操作过多
越来越多请求无法通过cache满足
多台DB服务器可以优化什么?
解决存不下:存储解决忙不过:qps
那么tinyurl的主要问题是啥?存储是没问题的,重点是qps。如何sharding呢?
垂直拆分:将多张表分别分配给多台机器。对此不适用,只有两列,无法再拆分。
横向拆分:
若id、shortURL做分片键:
long2short查询时,只能广播给N台db都去查询为何要查long2short?避免重复创建呀若不需要避免重复创建,则这样可行
用longurl做分片键:
short2long查询时,只能广播给N台DB查询。
1分片键选择
若一个long可对应多个short
使用cache缓存所有long2short在为一个longurl创建shorturl时,若cachemiss,则创建新short
若一个long只能对应一个short
若使用随机生成算法两张表,一张存储long2short,一张存储short2long每个映射关系存两份,则能同时支持long2shortshort2long查询若使用base62进制转换法有个严重问题,多台机器之间如何维护一个全局自增的id?一般关系型DB只支持在一台机器上实现这台机器上全局自增的id
4全局自增id
1专用一台DB做自增服务
该DB不存储真实数据,也不负责其他查询。
为避免单点故障,可能需要多台DB。
2使用zk
但使用全局自增id不是解决tinyurl最佳方案。GeneratingaDistributedSequenceNumber
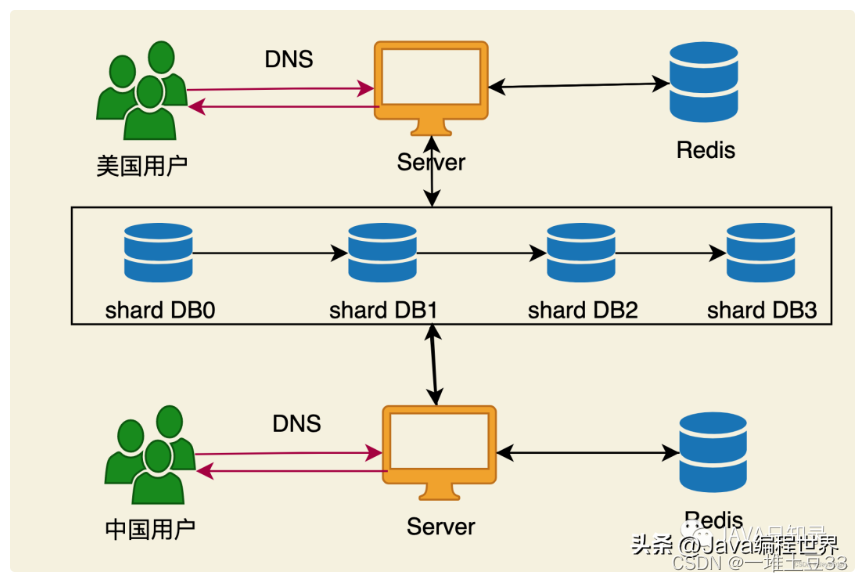
5基于base62的分片策略
Hash%62作为分片键
并将hash%62直接放到shorturl
若原来的shortkey是AB123则现在的shortkey是
hash%62+AB1234若hash%62=0,那就是0AB1234
这样,就能同时通过short、long得到分片键。
缺点:DB的机器数目不能超过6
最后最佳架构:
6还能优化吗?
webserver和database之间的通信。
中心化的服务器集群和跨地域的webserver之间通信较慢:如中国的Server需访问美国的DB。
为何不让中国的Server访问中国的DB呢?
若数据重复写到中国DB,如何解决一致性问题?很难解决!
思考用户的习惯:
中国用户访问时,会被DNS分配中国的服务器中国用户访问的网站一般都是中国的网站所以可按网站的地域信息来sharding如何获得网站的地域信息?只需将用户常访问的网站汇总在一张表。中国用户访问美国网站咋办?就中国server访问美国db,也不会慢太多中访中是用户主流,优化系统就是针对主要需求
于是,得到最终架构:
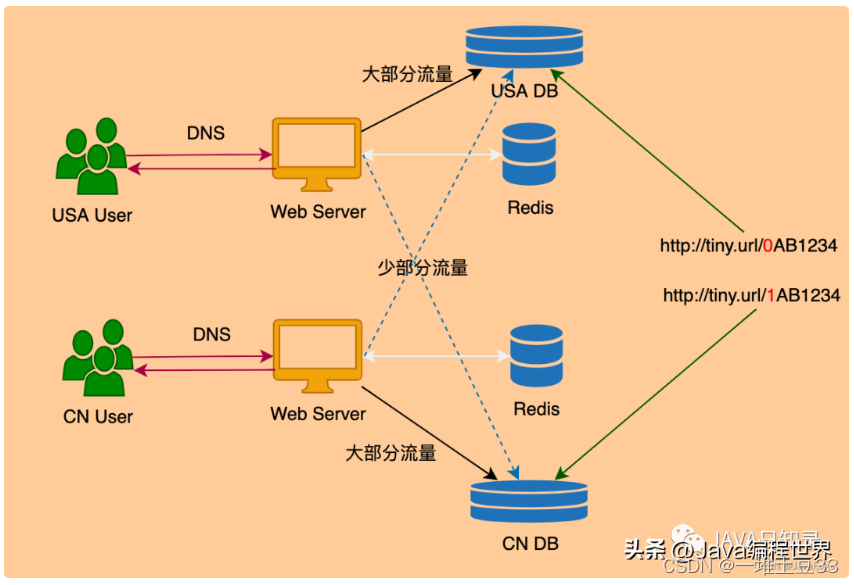
还可以维护一份域名白名单,访问对应地域的DB。
5用户自定义短链接
实现一个顾客短网址,使得顾客能创立他们自己的短网址。即你需要在前文基础上再实现一个createCustom。
需实现三个方法:
注意:
long2Short生成的短网址的key的长度应该等于可以使用的字符只有[a-zA-Z0-9]。如:abcD9E任意两个长的url不会对应成同一个短url,反之亦然如果createCustom不能完成用户期望的设定,那么应该返回"error",反之如果成功将长网址与短网址对应,应该返回这个短网址
在URLTable里,直接新增一列custom_url记录对应的customurl是否可行?
不可行!对于大部分数据,该列其实都为空,就会浪费存储空间。
新增一个表,存储自定义URL:CustomURLTable。

先查询CustomURLTable是否存在再在URLTable查询和插入
同前文一样,用两个哈希表处理长网址和短网址之间的相互映射关系。需额外处理的是用户设定的网址与已有冲突时,需返回"error"。注意:若用户设定的和已有恰好相同,则同样应该返回短网址。
2基于随机生成算法
无需做任何改动,直接把customurl当shorturl创建即可!
文章为作者独立观点,不代表 股票程序化软件自动交易接口观点



股民评论